HTML: La tela de la araña
Jordi Adell
Net Conexión, nº2, diciembre 1995
La página contiene texto e imágenes. Algunas palabras son de color azul. Hacemos clic sobre ellas con el ratón y tras unos segundos aparece la primera página de una revista electrónica. Introducimos algunos términos de búsqueda en un recuadro y una base de datos nos brinda una colección de documentos relacionados. Señalamos sobre un icono y oímos una melodía o vemos un pequeño fragmento de video. Es Internet y el World-Wide Web, la aplicación que más ha contribuido a su popularización. Los documentos hipermedia y sus vínculos hipertextuales forman una tela de araña de decenas de miles de nodos en todo el mundo. Una tela tejida con una sustancia especial: el HTML.
El HTML o «HyperText Markup Language» es el lenguaje en el que están escritos los hipertextos en el World-Wide Web (WWW). Se trata de un conjunto relativamente simple de especificaciones estandarizadas que permiten identificar en un texto sus partes fundamentales (como el título, el cuerpo del documento, los encabezamientos de cada una de sus partes, los diferentes párrafos, etc.). También podemos incluir mediante el HTML algunas opciones de formato (como separadores, negrita, itálicas, hacer listados, etc.). Podemos crear vínculos hipertextuales (o ‘links’) a otros documentos o ficheros de la Internet de tal forma que con un simple clic de ratón aparezcan en la pantalla, aunque se hallen en la otra parte del mundo. Nos permite insertar imágenes junto al texto, en incluso definir alguna zona de la imagen como un vínculo hipertextual. Finalmente, podemos crear formularios para que el usuario interactúe de modo complejo con sistemas informáticos como bases de datos y otras aplicaciones y servicios.
HTML y SGML
El HTML es en realidad una aplicación del estándar ISO 8879:1986 «Information Processing Text and Office Systems: Standard Generalized Markup Language» (SGML). El SGML es un meta-lenguaje mediante el cual se pueden definir tipos de documentos estructurados y lenguajes de marcas para representar ejemplos o instancias de este tipo de documentos. Es decir, un lenguaje diseñado para describir otros lenguajes. El SGML es un lenguaje esencialmente declarativo y no procedural, es decir, sólo identifica los elementos de un documento y no prescribe qué debe hacerse con dichas partes o elementos. El SGML pretende definir formas de codificar textos independientemente de sistemas informáticos. Como todo lenguaje de marcas, el HTML especifica qué marcas están permitidas, cuáles son además obligatorias, cómo pueden distinguirse del texto que constituye el contenido y, a la postre, qué significan las marcas.
Lo que NO es el HTML es un lenguaje para describir la apariencia de los documentos hipermedia. En demasiadas ocasiones nos encontramos con páginas en las que se fuerza el HTML para que tengan la apariencia buscada por el autor en un determinado agente de usuario o cliente WWW, olvidando el auténtico propósito del HTML y la existencia de usuarios que utilizan otros clientes. El HTML puede conjugarse con otras especificaciones (como hojas de estilo) para asegurar al autor el control sobre la apariencia de sus documentos, pero como tal, es el desarrollador del ‘browser’ quien decide si la cabecera de nivel 2 se representa en negrita y con un tipo de 14 puntos o subrayando el texto normal. En definitiva, el HTML no es un mal lenguaje de autoedición, sino una forma independiente de plataformas y sistemas de marcar textos para que sus diferentes partes y elementos sean posteriormente identificables de modo automatizado.
El HTML es texto
Un documento HTML es una secuencia de caracteres organizada físicamente en un conjunto de entidades (que poseen un nombre, atributos y contenido) y lógicamente como una jerarquía de elementos. Un documento HTML no es más que texto (ASCII o ISO Latin 1) que incluye una serie de elementos (como cabeceras, listas, formularios, vínculos hipertextuales, etc.), que pueden tener atributos. Cada elemento se delimita mediante marcas (o ‘tags’ en la jerga HTML). El ‘tag’ inicial comienza con el carácter < y termina con > y contiene el nombre del elemento y sus atributos. El ‘tag’ final comienza con los caracteres . Por ejemplo, para indicar que una cadena de caracteres debe representarse destacada respecto al texto normal se utiliza el elemento STRONG del siguiente modo: <STRONG>Este texto debe destacarse</STRONG>.
Algunos elementos sólo poseen una etiqueta inicial, por ejemplo, <HR> (que significa ‘horizontal rule’ o separador horizontal). En otras, la marca final es opcional (en los párrafos es opcional cerrar con </P> ya que queda suficientemente claro que un párrafo termina donde comienza otro o donde aparece la marca inicial de otro elemento que implica un nuevo párrafo).
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"><HTML> <HEAD> <TITLE>Documento HTML simple</TITLE> </HEAD> <BODY> <!-- Esta línea es un comentario: no aparecerá en el agente de usuario --> <H1>Documento simple HTML</H1> <HR> Este documento es un ejemplo de documento escrito en HTML. <P>Contiene una <STRONG>lista ordenada</STRONG>: <P><OL> <LI>La declaración; <LI>la cabecera; y <LI>el cuerpo del documento. </OL> <HR> Además de varios separadores horizontales, se incluye un vínculo hipertextual al <A href="http://www.uji.es/spain_wwww.html"> Mapa de Recursos Internet de España </A> y un formulario simple: <HR> <FORM METHOD="GET" ACTION="http://www.uji.es/cgi-bin/test"> Seleccione su fruta preferida: <BR> <SELECT NAME="fruta" SIZE = "4"> <OPTION>Peras <OPTION>Manzanas <OPTION>Plátanos <OPTION>Naranjas <OPTION>Otra </SELECT> <INPUT TYPE="reset" NAME="reset" VALUE="Borrar"> <INPUT TYPE="submit" NAME="submit" VALUE="Enviar"> </FORM> <HR> </BODY> </HTML>
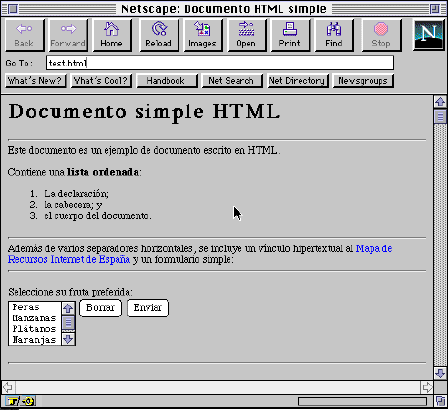
Figura 1: Ejemplo de texto HTML y cómo aparece en un cliente WWW
Esta es la mecánica del HTML. Sencilla y potente, sobre todo para lo que ha sido concebida. Su misión fundamental es generar documentos independientes de sistemas y plataformas. El HTML posee niveles (1, 2 y 3, de momento) que en realidad definen momentos de su evolución. En la actualidad se acaba de publicar la especificación oficial del HTML nivel 2.0 y se trabaja en la del HTML 3.0.
La estructura de un documento HTML
Un documento HTML puede representarse como un «árbol» de elementos que incluye:
– Una declaración (en el caso del HTML nivel 2.0 es: «<!DOCTYPE html PUBLIC «-//IETF//DTD HTML 2.0//EN»>»). La declaración indica a las aplicaciones que ‘leen’ el documento cual es el nivel de HTML empleado. Técnicamente, identifica el DTD (‘Definition Type Document’) SGML empleado en el documento. Casi todos los clientes ignoran la declaración. No así otras aplicaciones como analizadores sintácticos o ‘parsers’, que comprueban su corrección.
– Tras la declaración va el elemento <HTML>, que contiene a su vez:
<P>
- Una cabecera (que va entre las marcas <HEAD> y </HEAD>) en la que se incluye información sobre el documento considerado globalmente como un todo. Entre dichos elementos destacan el título (TITLE), la dirección-base para resolver los URLs relativos (BASE) (véase más abajo el apartado sobre URLs), el indicador de la facilidad de búsqueda (ISINDEX), meta-información asociada (META), etc.
- El cuerpo del documento (entre <BODY> y </BODY>), que incluye el texto a representar con sus vínculos hipertextuales, imágenes inscritas, formularios, etc. Dentro de estos elementos pueden figurar otros, como encabezamientos, listas, formularios, vínculos, etc.
Algunos elementos es preemtivo que aparezcan sólo dentro de un elemento dado (por ejemplo, el elemento TITLE, que indica el título del documento, sólo puede aparecer dentro de la cabecera, es decir, entre las etiquetas <HEAD> Y </HEAD>). Otros son opcionales (por ejemplo, se pueden separar los ítems de una lista con marcas de párrafo).
<
Algunos agentes de usuario son tolerantes y admiten documentos en los que no figuran alguno de los elemento anteriores. Sin embargo, conviene incluirlos a fin de asegurarnos de que nuestro documento será legible para todos los agentes de usuario, incluyendo los que puedan desarrollarse en el futuro, que puede que respeten la norma de modo más estricto que los actuales.
No van a describirse todos los elementos (y sus atributos) del HTML nivel 2.0. Sin embargo, si tuvieran que resumirse los agruparíamos en:
1. Elementos de estructuración del documento
Son aquellos que definen las partes básicas de todo documento HTML: la declaración, el elemento HTML, la cabecera (HEAD) y el cuerpo (BODY), que contiene el texto y demás información que mostrará el agente de usuario.
2. Elementos meta-informativos.
Usualmente incluidos en la cabecera, este tipo de elementos proporcionan información al agente de usuario sobre el documento como un todo. Entre ellos destacaremos el título (TITLE), la dirección base para resolver los URLs relativos (BASE), el indicador de la facilidad de búsqueda (ISINDEX), meta-información asociada (META), etc.
3. Elementos para la estructuración de bloques.
Los elementos estructurantes de bloques incluyen párrafos (P), formatos de texto (PRE, ADDRESS y BLOCKQUOTE). Se utilizan para determinar la naturaleza y/o apariencia de un bloque de texto.
4. Listas y menús
Diferentes tipos de listados (desordenados (UL, LI), ordenados (OL, LI), directorios (DIR), menús (MENU), de definición (DL, DT, DD) permiten organizar el texto de modo que el agente realice automáticamente algunas tareas (por ejemplo, insertar número de orden o indentar ciertas líneas) y represente adecuadamente una enumeración de ítems.
5. Elementos de usos idiomáticos
Las frases pueden ser marcadas de acuerdo con su uso idiomático (como en una cita textual), su apariencia tipográfica (negrita) o para ser utilizadas como vínculos hipertextuales. Cita (CITE), código (CODE), énfasis (EM), teclado (KBD), muestra (SAMP), énfasis fuerte (STRONG) o una variable (VAR) son ejemplos de uso idiomático.
6. Elementos tipográficos
En este apartado incluiríamos los elementos negrita (B), itálica (I) y teletipo (TT). Constituyen instrucciones concretas sobre cómo debe representarse el contenido de dichos elementos, por eso se denominan también estilos físicos, frente a los anteriores, estilos lógicos.
7. Vínculos hipertextuales
El elemento indica un vínculo hipertextual. Con el atributo HREF (y el URL asociado) indica el destino de un salto hipertextual. Con el atributo NAME puede ser el punto de llegada de un salto hipertextual.
8. Separadores
Los elementos HR (‘horizontal rule’) y BR (‘break’) permiten separar unidades lógicas de un texto con una línea horizontal o bien indicar un retorno de carro.
9. Imágenes
El elemento IMG sirve para incluir una imagen en el documento a través de un vínculo hipertextual. Con el URL asociado podemos incorporar cualquier imagen accesible en Internet. El atributo ISMAP indica que es una imagen «sensible» y que el usuario podrá señalar una región y recuperar el objeto asociada a ésta.
10. Formularios
Los formularios permiten que el usuario introduzca información (seleccionando ítems o directamente escribiendo en los lugares indicados) que será procesada por ‘scripts’ asociados al servidor de acuerdo con la especificación CGI (‘Common Gateway Interface’). Elementos como FORM, INPUT, SELECT, TEXTAREA y sus atributos permiten diseñar formularios que rellenará el usuario. Sin embargo, su funcionalidad no deviene del HTML sino de los ‘scripts’ ejecutables que residen en el servidor y que reciben la información introducida por el usuario.
Acentos, eñes y cedillas
Un error extendido acerca del HTML es que para representar adecuadamente los acentos y otros caracteres no-ASCII es necesario poner cosas como «á» y «ñ». Esto es falso. El protocolo del WWW (http) transmite 8 bits y el juego de caracteres oficial del WWW es el ISO Latin 1 (ISO 8859-1). Mediante ISO Latin-1 se pueden representar la mayoría de los idiomas europeos occidentales (como catalán, castellano, francés, etc.). Si el ordenador puede producir ISO Latin-1 (y hay utilidades para traducir automáticamente los juegos de caracteres de cualquiera de ellos) no hace falta ‘escapar’ los caracteres acentuados: han sido pensados para los ordenadores que no utilizan ese juego de caracteres. Además, si se pretende indexar los documentos del servidor WWW se complicará el tema de las búsquedas: la pasarela tendrá que ‘escapar’ los términos de búsqueda de los usuarios.
Los URL
Un URL (o ‘Uniform Resource Locator’) es «la sintaxis y semántica de información formalizada para la localización y el acceso a recursos a través de Internet». Dicho así (RFC 1738) parece un arcano, sin embargo es una idea sencilla y potente. De hecho es, tal vez, la clave del WWW. Los URL se utilizan en el WWW para ‘localizar’ recursos. Proporcionan, de forma compacta, inteligible para los humanos e interpretable para aplicaciones informáticas la información básica que permite acceder a un recurso en la Internet: el protocolo de acceso (http, ftp, gopher, wais, nntp, etc.), el ordenador remoto en el que se encuentra (y el puerto en el que ‘escucha’ dicho protocolo si no es el estándar) y una forma de identificar el recurso en cuestión (el ‘camino’ a seguir por la estructura jerárquica de ficheros, un identificador único, etc.) o de interactuar con él (las palabras clave a buscar, por ejemplo).
Una vez localizado el recurso, el sistema puede realizar las operaciones pertinentes: trasferir una copia y mostrarla al usuario o almacenarla, interrogar una base de datos, iniciar una sesión remota, actualizar el recurso, solicitar sus atributos, etc. Cada protocolo permite diferentes operaciones y la sintaxis URL se ha diseñado de modo que pueda ampliarse a futuros protocolos.
Los URL nos permiten realizar ‘saltos hipertextuales’ por la Internet. Son lo que se esconde tras las palabras o frases marcadas como vínculos y ‘ordenan’ al agente de usuario que ha de hacer cuando el usuario las señala (haciendo clic sobre ellas, por ejemplo).
Aplicaciones HTML
Las aplicaciones que ‘tratan’ con textos HTML son de diversos tipos y cumplen diversos propósitos:
1. Los agentes de usuario, conocidos como ‘browsers’ o ‘clientes WWW’, son componentes de un sistema distribuido que presentan un interface y procesan las peticiones de los usuarios. Un agente de usuario WWW realiza, pues, dos funciones básicas: presenta la información ante el usuario y transmite las peticiones del usuario a los servidores WWW. Netscape, Mosaic, Lynx, Cello, etc. son agentes de usuario. En la actualidad existen agentes para casi cualquier tipo de plataforma informática. Los hay comerciales y gratuitos. En el último FAQ («Frequently Asqued Questions») sobre el WWW se listaban nada menos que 50 agentes diferentes.
Los agentes de usuario se apoyan en aplicaciones auxiliares para representar o actuar sobre los formatos de ficheros que no pueden manejar directamente (algunos formatos gráficos, de sonido o video, de compresión y codificación de ficheros, etc.). Los agentes de usuario son cada vez más políglotas (entienden y hablan cada vez más protocolos) y se integran mejor con el entorno del usuario. En un futuro próximo sólo será necesaria una aplicación para acceder a toda la información de Internet.
En <URL: http://www.halsoft.com/html-val-svc/> hay un formulario que permite introducir el URL de nuestra página (o fragmentos si no está todavía en el servidor o tenemos dudas) y seleccionar el nivel HTML para el que pretendemos validar nuestro documento. Otras aplicaciones de validación incluyen:
Weblint (<URL:http://www.khoros.unm.edu/staff/neilb/weblint.html>) y Htmlchek <URL:http://uts.cc.utexas.edu/~churchh/htmlchek.html>.
4. Conversores. Hay utilidades que ‘traducen’ de un formato de texto a HTML (por ejemplo, de PostScript o RTF a HTML). Sin embargo, se tiene que introducir a mano los ‘links’ en el texto HTML generado (o preparar cuidadosamente el texto antes, con lo que la ventaja de la conversión automática desaparece). Son útiles cuando es necesario convertir masivamente textos con formato. El resultado suele tener buena apariencia, aunque la mayor parte de las veces tendrá que retocarlo a mano.
5. Las pasarelas entre sistemas diversos convierten texto (u otras cosas) en HTML ‘on the fly’. Se trata de aplicaciones que leen documentos en otro formato e insertan marcas en lugares predeterminados de, por ejemplo, documentos dinámicos producto de un ‘query’ a una base de datos. Las pasarelas son útiles sólo para ciertos propósitos y consumen más CPU que la recuperación simple de ficheros almacenados en el servidor.
En conclusión
El HTML es un lenguaje fácil de aprender y utilizar. Existe mucha información en la red, incluyendo manuales, tutoriales, software de edición, traducción y utilidades diversas, como analizadores sintácticos. Tal vez el único problema con el HTML es que todavía no permite hacer lo que los nuevos usuarios demandan, sobre todo en sectores comerciales. Sin embargo, los nuevos desarrollos (HTML 3.0, Java, VRML, hojas de estilo, etc.) auguran mucha excitación y diversión para los próximos meses.
Recuadro:
Netscapismos
El reciente lanzamiento de nuevas versiones del conocido agente de usuario Netscape Navigator (que todo el mundo de habla hispana se esfuerza por no llamar «Navegante») ha reavivado una polémica que colea ya hace tiempo por la Internet: el mayor o menor grado de cumplimiento de los estándares por parte de los desarrolladores de aplicaciones. En lo que se ha calificado de estrategia puramente comercial y de afanes monopolísticos, algunos desarrolladores (Netscape y Microsoft, por ejemplo) han creado elementos nuevos no conformantes con el estándar HTML. Algunas de ellos pertenecen, previsiblemente, al HTML 3.0 (como las tablas, aunque el modelo recién propuesto para el HTML 3.0 es más completo que el de Netscape) otras son de cosecha propia y han sido acogidos con franca repulsa cuando no burla (por ejemplo, el <BLINK>, del Netscape Navigator) por los sectores más comprometidos con una evolución consensuada y racional del HTML. El problema es que, una vez hemos sacado la pasta de dientes es imposible volverla a meter en el tubo. Muchos servidores exiben el rótulo «Optimizado para Netscape». Es evidente que esta política va en contra de toda la filosofía con la que se ha desarrollado el WWW y que subyace al SGML y al HTML: independencia de plataformas hardware/software.
La presión del mercado, en la línea de hacer más estéticas las páginas del WWW, y la necesidad de capturar parte de dicho mercado en un ‘negocio’ en el que existen numerosos y excelentes productos gratuitos han movido a estas empresas a no esperar más y a implementar elementos que todavía se hallan en fase de estudio y discusión o a inventarse nuevos elementos a medida de las necesidades de sectores de mercado. Dichos nuevos elementos son, en su mayor parte, cosméticos y orientados sólo a mejorar la apariencia del documento.
Como principio recomendaríamos cautela en el uso de dichos elementos no estándar, sobre todo de los que comprometan la estructura y funcionamiento del documento o conjunto de documentos y, desde luego, olvidar el desafortunado <BLINK> (que nos retrotrae a la época de los terminales tontos). Un aspecto divertido del tema es que un error en el Netscape Navigator versión 1.1 (es decir, un comportamiento no pretendido por sus desarrolladores) se ha convertido en un elemento obligado en las páginas de algunos autores: múltiples elementos <TITLE> que generan un título que se escribe desde el centro del título de la ventana hacias ambos lados y paso a paso. Lo sentimos: es un ‘bug’ no un ‘tag’. La version 2 ya no lo hace. El efecto de recuperar documentos HTML con 25 elementos <TITLE> en la misma página mediante una pasarela a una base de datos que indexe el contenido de un servidor es fastuoso.
Recuadro
Cómo aprender HTML
Hay varios libros (y es previsible que aparezcan más en breve) orientados a enseñar HTML. Sin embargo los libros, por su largo proceso de producción y distribución y dado el dinamismo del WWW, no reflejan lo «último». Para ello es conveniente utilizar las fuentes «online». También podremos conseguir ayuda y software.
Libros:
- Graham, Ian S. (1995). The HTML Sourcebook, John Wiley and Sons. ISBN: 0-471-11849-4. Revisión en <URL:http://mirror.wwa.com/mirror/reviews/books/95/htmlsb.htm>
- Lemay, Laura (1995). Teach Yourself Web Publishing with HTML in a Week. Sams Publishing. ISBN: 0-672-30667-0. <URL:http://slack.lne.com/lemay/theBook/index.html>
- Aronson, Larry (1995). The HTML Manual of Style. Ziff-Davis Press.
- Morris, Mary (1995). HTML Authoring for Fun & Profit. Prentice Hall. ISBN:0-13-359290-1.
Manuales «online»:
Hay multitud de manuales en la red para aprender HTML. Para novatos, el más conocido es: «A beginner’s guide to HTML» del NCSA. Puede obtenerse en <URL:http://www.ncsa.uiuc.edu/General/Internet/WWW/HTMLPrimer.html>. Después pueden consultarse alguno de los listados en Yahoo (<URL:http://www.yahoo.com/Computers/World_Wide_Web/> o en la W3 Organization <URL:http://www.w3.org/pub/WWW/MarkUp/MarkUp.html>
Netnews:
Software:
Existen multitud de editores, conversores y utilidades relacionadas con el HTML. La lista sería interminable y, además, no hay semana que no aparezcan nuevas aplicaciones. Es conveniente revisar periódicamente en los servidores citados anteriormente (Yahoo, W3 Org., etc.) las secciones dedicadas al software. Para los usuarios de entorno Macintosh, uno de los editores más populares ha sido desarrollado en la Universitat Jaume I. Se trata de las BBEdit HTML Extensions, un conjunto de extensiones para un editor (BBEdit), una de cuyas versiones es gratuita (BBEdit Lite), que permiten insertar fácilmente ‘marcas’ HTML en un texto. El autor es Carles Bellver y pueden obtenerse gratuitamente en <URL:http://www.uji.es/bb-html-ext-info.html>.
Listas de discusión:
También existen listas de discusión relacionadas con el desarrollo del HTML. La lista completa está en <URL:http://www.w3.org/hypertext/WWW/Mail/Lists.html> y en <URL:http://www.w3.org/hypertext/WWW/Mail/Outside_mailing.html>. Y la dedicada específicamente a HTML (denominada www-html) y de caráter técnico puede verse en <URL:http://www.eit.com/www.lists/>.
Los trucos del oficio:
Finalmente un truco: en HTML casi todo está a la vista. Si una página le parece especialmente brillante, mire cómo está hecha. No olvide, sin embargo, que el HTML es un estándar y que no todo lo que hay en el Web es HTML correcto: utilice un ‘parser’ para comprobar su corrección. En el futuro agradecerá haberlo hecho.
Recuadro
EL FUTURO: HTML 3.0
Algunas de las posibilidades del HTML nivel 3.0 ya han sido implementadas en conocidos clientes WWW (aunque de modo un tanto peculiar). Pero lo más destacable que veremos en un futuro inmediato son: tablas sofisticadas, un nuevo elemento gráfico