Índices electrónicos en el World-Wide Web
Carles Bellver Torlà
Este artículo se publicó originalmente en el número de febrero de 1996 de la revista Net Conexión.
En el estado actual del World-Wide Web la abundancia de recursos online puede resultar ya un problema. En ocasiones, lo difícil es localizar o seleccionar lo relevante: no perderse en la telaraña y encontrar el camino más corto hasta la información que buscábamos.
Una de las facilidades más apreciadas por los usuarios de la red son los servicios de exploración, como Lycos o InfoSeek, capaces de mantener bases de datos de todo el contenido del WWW y llevar a cabo cualquier búsqueda: si quiero encontrar unas cuantas páginas firmadas por Nicholas Negroponte, no tengo más que teclear su nombre en un formulario y sentarme a esperar una lista de enlaces.
Sin duda este tipo de robots exploradores nos hacen la vida más fácil a todos, pero en cualquier caso no eximen a un webmaster de sus obligaciones. Una de sus táreas consiste precisamente en hacer que la información disponible en el servicio que administra se pueda hallar fácilmente. Si uno recuerda que en EuroInfo dió casualmente con las fotografías de los miembros de la Comisión Europea, y al volverse a conectar le resulta imposible encontrarlas, la culpa no es suya, sino del administrador del servicio. Es responsabilidad suya proporcionar las herramientas de navegación, entre ellas alguna herramienta de búsqueda que permita preguntar por Marcelino Oreja y llegar hasta su foto.
Aquí es donde interviene WAIS. Brewster Kahle, fundador y presidente de WAIS Inc. declaraba en septiembre pasado a Internet World: «Nos gusta usar esta analogía: un libro tiene tres secciones, la tabla de contenidos, las páginas, y el índice analítico. Así que pensemos en la Internet como en un libro: está Gopher, que es la tabla de contenidos; está el World-Wide Web, que son las páginas de hipertexto; y está WAIS, que es una búsqueda directa cuando sabes lo que quieres.» Cuando uno sabe lo que busca, y sólo le falta encontrarlo, tiene WAIS, que sería algo así como un índice analítico para el WWW. Pero WAIS no se ha conformado siempre con este papel secundario. En un principio aspiraba a ser mucho más.
Radiografía de un perdedor
WAIS empezó en 1989 como un proyecto conjunto de Thinking Machines, Apple Computer y Dow Jones. La idea era, entonces, ambiciosa: sentar las bases para convertir las redes de comunicaciones en un nuevo y potente medio de distribución de la información, tan nuevo y tan potente que llegaría a cambiar el mundo (eso afirmaban literalmente algunos papeles divulgativos). Se consideraba que en un futuro más que inmediato, ya inminente, los documentos iban a residir tanto en el disco duro de nuestro ordenador personal como en otros discos accesibles por la red. Resultaba claro que a medida que fuese aumentando la capacidad de los discos y se interconectaran las redes, la cantidad de datos accesibles iría superando las posibilidades de los árboles de ficheros de las plataformas Unix, Macintosh y MS DOS. El problema fundamental podía ser ése, la dificultad de hallar la información. Miles de documentos podían llegar a acumular polvo en el fondo de los subdirectorios, y la posibilidad de buscarlos por su nombre no bastaría para rescatarlos. Se requeriría, también, buscarlos por su contenido: algo así como preguntar en castellano (en inglés en el original) «¿Qué hay escrito sobre perl y CGI?» y obtener una lista de documentos, que podrían estar en mi disco duro o en cualquier otro punto de la red.
El sistema WAIS se diseñó para hacer posible tal cosa. La arquitectura elegida fue cliente-servidor. Nuestros ordenadores personales actuarían como clientes de servidores WAIS, encargados de mantener y consultar para nosotros bases de datos de conjuntos de documentos, y devolvernos el resultado de las consultas. En este esquema habría que distinguir varios elementos:
- El cliente
- Permite al usuario: seleccionar la base de datos que desea consultar, remitir la pregunta al servidor, examinar la lista de documentos obtenida y recuperar y visualizar cualquiera de esos documentos.
- El servidor
- Se encarga de recibir y procesar las consultas de los clientes, buscar en los índices de la base de datos qué documentos son relevantes y remitir la lista al cliente. Después, si éste lo solicita, puede enviarle documentos completos.
- El protocolo
- Se basó en el estándar NISO Z39.50-1988, con extensiones para el soporte de multimedia (es decir, la posibilidad de emplear información de diversos tipos: texto normal, buzones de correo, imágenes GIF, etc.)
- La base de datos
- Contiene los documentos originales (textos, gráficos, etc.) junto con índices completos de todas las palabras que aparecen en los documentos. Estos indices posibilitan búsquedas más rápidas y eficaces.
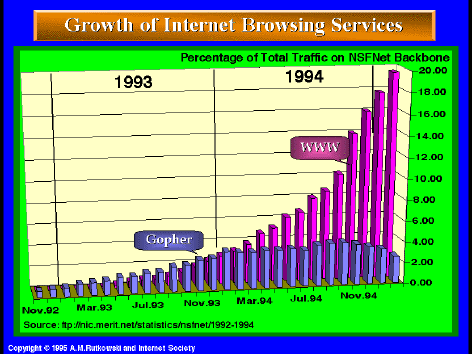
En 1992 había en Internet unos pocos cientos de bases de datos WAIS de acceso público. Se utilizaban cómo índices de la Biblia, de ciertos grupos de news y listas de correo, y de todo tipo de información especializada. Eran un recurso enormente productivo para usuarios profesionales. Si un consultor informático quería aclarar qué tipos de tarjetas Ethernet servían para un Macintosh LC, era más rápido y seguro consultar la base de datos WAIS de Info-mac que telefonear a un proveedor. Cualquier intervención que sobre este tema se hubiese hecho en la lista de correo de Info-mac podía estar en su pantalla en cuestión de segundos, o minutos. El sistema, sin embargo, no resultaba tan atractivo para el usuario ocasional que no tenía nada que preguntar. WAIS es muy educado: no habla si no se le pregunta primero. Esa fué la ventaja de sistemas como el Gopher y el World-Wide Web: de entrada presentan ya información al usuario que aún no sabe lo que quiere (una home page, un mensaje de bienvenida, algunos enlaces…) y de este modo le permiten comenzar a navegar por la red. De ahí el éxito de los nuevos sistemas y la explosión de la Internet a partir de 1993.
Si no puedes vencerlos…
Mosaic primero, y Netscape después, convirtieron el WWW en el interface principal de la Internet. WAIS tuvo que abandonar entonces el sueño dorado de cambiar el mundo él solo, pero al menos ha podido hacerse sitio en un discreto segundo plano. El hecho era que el diseño inicial del WWW no contemplaba la posibilidad de realizar búsquedas, y de eso puede encargarse WAIS. En la entrevista con B. Kahle que citábamos al comienzo del artículo, éste afirma: «Si tenemos éxito, nadie sabrá que está usando WAIS … Sólo estamos interesados en ser la parte de atrás, y la fontanería sólo se nota cuando funciona mal. Así que nuestro objetivo es estar fuera de vista y trabajar.»
Los servidores HTTP incorporan un mecanismo de extensión estándar para comunicarse con aplicaciones externas: el Common Gateway Interface (CGI). Esto les permite incrementar sus capacidades; por ejemplo, integrar WAIS como motor para la realización de búsquedas. Para ello, se requiere:
- Mantener actualizada regularmente una base de datos WAIS de los documentos HTML que constituyen el contenido del servidor.
- Instalar en el servidor WWW los formularios de búsquedas pertinentes y un programa CGI que recoja las preguntas, las use en una consulta WAIS, y formatee el resultado como una lista de enlaces que lleven a los documentos relevantes.
El propósito de las pasarelas WWW-WAIS no es otro, pues, que traducir las preguntas formuladas por el usuario a un formato que entienda WAIS, y traducir las respuestas de WAIS a un formato de hipertexto válido para el WWW. El usuario teclea «Marcelino Oreja» en un campo de texto, y obtiene una lista de enlaces a los documentos que mencionan estas palabras.
Más allá de las búsquedas
El sistema WAIS estaba pensado para que el usuario de las redes controlara qué información quería. Pero el usuario no sabía lo que quería, o ni siquiera quería nada en especial. El Gopher y el World-Wide Web le dieron precisamente eso, cualquier cosa. Pero a la larga el usuario aprende a seleccionar los recursos y aprovecharlos para su trabajo, y entonces se hace más exigente. WAIS, desde la parte de atrás, puede ayudarle a ganar el control.
Lo cierto es que la utilización actual de WAIS en el WWW suele ser bastante limitada: meros formularios de búsquedas. Pero se intenta ya elaborar otras posibilidades más imaginativas y de gran potencial. Una de las sugerencias iniciales de Brewster Kahle para el interface de WAIS fueron las llamadas «carpetas dinámicas», una especie de cruce entre una consulta a una base de datos y una carpeta del Mac. Una carpeta dinámica estaría asociada a una consulta, y su contenido virtual sería el resultado de la consulta. Este contenido podría actualizarse automáticamente cada vez que cambiase el contenido de la base de datos o se reformulase la consulta. La idea de las carpetas dinámicas nunca llegó a desarrollarse como interface del sistema WAIS. Ahora, su incorporación al WWW tendría aplicaciones muy interesantes. Una serían los filtros de listas de correo y grupos de news, de manera que sólo nos llegaran los mensajes posiblemente interesantes. Otra podría ser el periódico personal, el famoso «Daily Me». El lector definiría sus preferencias: qué secciones le interesan más, qué agencias de noticias, editores o articulistas le merecen más confianza, etc. Usando estos perfiles, WAIS podrá buscar en las bases de datos, seleccionar los contenidos y confeccionar publicaciones a la medida del lector. Con WAIS en la rotativa cortando y pegando, el WWW podrá servirle su periódico cada mañana, o cada media hora, o cuándo él quiera.